Java基础
面向对象六原则一法则
单一职责原则(Single-Resposibility Principle)
一个类只做它该做的事情。(单一职责原则想表达的就是"高内聚",写代码最终极的原则只有六个字"高内聚、低耦合",所谓的高内聚就是一个代码模块只完成一项功能,在面向对象中,如果只让一个类完成它该做的事,而不涉及与它无关的领域就是践行了高内聚的原则,这个类就只有单一职责。另一个是模块化一个好的软件系统,它里面的每个功能模块也应该是可以轻易的拿到其他系统中使用的,这样才能实现软件复用的目标。)。
开放封闭原则(Open-Closed principle)
软件实体应当对扩展开放,对修改关闭。(在理想的状态下,当我们需要为一个软件系统增加新功能时,只需要从原来的系统派生出一些新类就可以,不需要修改原来的任何一行代码。要做到开闭有两个要点:1. 抽象是关键,一个系统中如果没有抽象类或接口系统就没有扩展点;2. 封装可变性,将系统中的各种可变因素封装到一个继承结构中,如果多个可变因素混杂在一起,系统将变得复杂而换乱,如果不清楚如何封装可变性)
Liskov替换原则(Liskov-Substituion Principle)
里氏替换原则,任何时候都可以用子类型替换掉父类型。(关于里氏替换原则的描述,Barbara Liskov女士的描述比这个要复杂得多,但简单的说就是能用父类型的地方就一定能使用子类型。里氏替换原则可以检查继承关系是否合理,如果一个继承关系违背了里氏替换原则,那么这个继承关系一定是错误的,需要对代码进行重构。例如让猫继承狗,或者狗继承猫,又或者让正方形继承长方形都是错误的继承关系,因为你很容易找到违反里氏替换原则的场景。需要注意的是:子类一定是增加父类的能力而不是减少父类的能力,因为子类比父类的能力更多,把能力多的对象当成能力少的对象来用当然没有任何问题。)代表约定、代表角色,能否正确的使用接口一定是编程水平高低的重要标识。)
依赖倒置原则(Dependecy-Inversion Principle)
面向接口编程。(该原则说得直白和具体一些就是声明方法的参数类型、方法的返回类型、变量的引用类型时,尽可能使用抽象类型而不用具体类型,因为抽象类型可以被它的任何一个子类型所替代,请参考下面的里氏替换原则。)
接口隔离原则(Interface-Segregation Principle)
接口要小而专,绝不能大而全。(臃肿的接口是对接口的污染,既然接口表示能力,那么一个接口只应该描述一种能力,接口也应该是高度内聚的。例如,琴棋书画就应该分别设计为四个接口,而不应设计成一个接口中的四个方法,因为如果设计成一个接口中的四个方法,那么这个接口很难用,毕竟琴棋书画四样都精通的人还是少数,而如果设计成四个接口,会几项就实现几个接口,这样的话每个接口被复用的可能性是很高的。Java中的接口代表能力、 分离的手段主要有以下两种:1. 委托分离,通过增加一个新的类型来委托客户的请求,隔离客户和接口的直接依赖,但是会增加系统的开销。2. 多重继承分离,通过接口多继承来实现客户的需求,这种方式是较好的。
合成聚合复用原则
优先使用聚合或合成关系复用代码。(通过继承来复用代码是面向对象程序设计中被滥用得最多的东西,因为所有的教科书都无一例外的对继承进行了鼓吹从而误导了初学者,类与类之间简单的说有三种关系,Is-A关系、Has-A关系、Use-A关系,分别代表继承、关联和依赖。其中,关联关系根据其关联的强度又可以进一步划分为关联、聚合和合成,但说白了都是Has-A关系,合成聚合复用原则想表达的是优先考虑Has-A关系而不是Is-A关系复用代码,原因嘛可以自己从百度上找到一万个理由,需要说明的是,即使在Java的API中也有不少滥用继承的例子,例如Properties类继承了Hashtable类,Stack类继承了Vector类,这些继承明显就是错误的,更好的做法是在Properties类中放置一个Hashtable类型的成员并且将其键和值都设置为字符串来存储数据,而Stack类的设计也应该是在Stack类中放一个Vector对象来存储数据。记住:任何时候都不要继承工具类,工具是可以拥有并可以使用的,而不是拿来继承的。)
迪米特法则
迪米特法则又叫最少知识原则,一个对象应当对其他对象有尽可能少的了解。再复杂的系统都可以为用户提供一个简单的门面,Java Web开发中作为前端控制器的Servlet或Filter不就是一个门面吗,浏览器对服务器的运作方式一无所知,但是通过前端控制器就能够根据你的请求得到相应的服务。调停者模式也可以举一个简单的例子来说明,例如一台计算机,CPU、内存、硬盘、显卡、声卡各种设备需要相互配合才能很好的工作,但是如果这些东西都直接连接到一起,计算机的布线将异常复杂,在这种情况下,主板作为一个调停者的身份出现,它将各个设备连接在一起而不需要每个设备之间直接交换数据,这样就减小了系统的耦合度和复杂度。
Java如何实现的平台无关
- Java语言规范
- 通过规定Java语言中基本数据类型的取值范围和行为
- Class文件
- 所有Java文件要编译成统一的Class文件
- Java虚拟机
- 通过Java虚拟机将Class文件转成对应平台的二进制文件等
JVM支持哪些语言(Kotlin、Groovy、JRuby、Jython、Scala)
值传递、引用传递
Java中只有值传递
public class Main {
public static void main(String[] args) {
int a = 10;
Integer b = 20;
int[] arr = {1, 2};
swap(a, b);
System.out.println(String.format("a:%d b:%d", a, b));
swap(arr);
System.out.println(Arrays.toString(arr));
}
// 对于对象而言传递的是对象引用的地址作为值
static void swap(int a, Integer b) {
int t = a;
a = b;
b = t;
}
static void swap(int[] arr) {
arr[0] = 996;
}
}
/**
OutPut:
a:10 b:20
[996, 2]
**/
- 值传递(pass by value)是指在调用函数时将实际参数复制一份传递到函数中,这样在函数中如果对参数进行修改,将不会影响到实际参数。
- 引用传递(pass by reference)是指在调用函数时将实际参数的地址直接传递到函数中,那么在函数中对参数所进行的修改,将影响到实际参数。
成员变量和方法作用域
| 作用域 | 当前类 | 同package | 子孙类 | 不同package |
|---|---|---|---|---|
| public | √ | √ | √ | √ |
| protected | √ | √ | √ | × |
| fridendly(默认) | √ | √ | × | × |
| private | √ | × | × | × |
例子:protected在其子类中可以访问,无论是子类内部还是子类的实例,无论它们是在哪个包中, 但如果子类与父类不在同一个包中,在子类中用父类的实例去访问的话不可以。
| 名称 | 说明 | 备注 |
|---|---|---|
| public | 可以被任何类访问 | |
| protected | 可以被同一包中的所有类访问 | 子类没有在同一包中也可以访问 |
| private | 只能够被 当前类的方法访问 | |
| 缺省无访问修饰符 | 只能够被 当前类的方法访问 | 如果子类没有在同一个包中,也不能访问 |
数据类型
八种基本数据类型:整型(byte8、short16、int32、long64)、浮点型(float32、double63)、布尔型(boolean8)、字符型(char16)。
自动转换顺序 从低到高的顺序转换。不同类型数据间的优先关系如下: 低———————————————>高 byte,short,char-> int -> long -> float -> double
“ 除了long和double类型,Java基本数据类型都是的简单读写都是原子的,而简单读写就是赋值和return语句。”因此而对于其他自加自减以及其他运算操作,是非原子操作。基本类型的数据对于其他线程来说不能保证是最新修改值,因此,声明为volative可以保证可视性。
对于32位操作系统来说,单次操作能处理的最长长度为32bit,而long类型8字节64bit,所以对long的读写都要两条指令才能完成(即每次读写64bit中的32bit)。如果JVM要保证long和double读写的原子性,势必要做额外的处理。不加volatile的话 ,并发情况下针对某个元素的访问可能出现脏读(cpu cache导致的),单纯的替换如果允许脏读的话 ,可以不加这些修饰符 ,如果涉及到非幂等操作 ,还是要用同步修饰符。
Integer的缓存机制
缓存支持-128到127之间的自动装箱过程。最大值127可以通过-XX:AutoBoxCacheMax=size修改。 缓存通过一个for循环实现。从低到高并创建尽可能多的整数并存储在一个整数数组中。这个缓存会在Integer类第一次被使用的时候被初始化出来。以后,就可以使用缓存中包含的实例对象,而不是创建一个新的实例(在自动装箱的情况下)。Java 5范围是固定的-128 至 +127。Java 6中,可以通过java.lang.Integer.IntegerCache.high设置最大值。根据应用程序的实际情况灵活地调整来提高性能。到底是什么原因选择这个-128到127范围呢?
Byte, Short, Long有固定范围: -128 到 127。对于Character, 范围是 0 到 127。除了Integer以外,这个范围都不能改变。
字符串的不可变性
String s1 = "asd";//s1保存String对象的引用
String s2 = s1;//s2保存为s1的引用
s1 = s1.replace("a", "asd");//保存新创建对象的引用
repalce源码,每次都产生一个新的String对象
public String replace(char oldChar, char newChar) {
if (oldChar != newChar) {
int len = value.length;
int i = -1;
char[] val = value; /* avoid getfield opcode */
while (++i < len) {
if (val[i] == oldChar) {
break;
}
}
if (i < len) {
char buf[] = new char[len];
for (int j = 0; j < i; j++) {
buf[j] = val[j];
}
while (i < len) {
char c = val[i];
buf[i] = (c == oldChar) ? newChar : c;
i++;
}
return new String(buf, true);//构造新的String对象
}
}
return this;
}
String拼接
String s = "a" + "b",编译器会进行常量折叠(因为两个都是编译期常量,编译期可知),即变成 String s = “ab”。
对于能够进行优化的(String s = “a” + 变量 等)底层是StringBuilder 的 append() 方法替代,最后调用 toString() 方法 (底层就是一个 new String()),Java本身是不支持运算符重载的。
对于Java的字符串拼接从效率比较:
StringBuilder>StringBuffer(synchronized)>concat>+>StringUtils.join
Arrays.asList获得的List使用时需要注意什么
- asList 得到的只是一个 Arrays 的内部类,一个原来数组的视图 List,因此如果对它进行增删操作会报错
- 用 ArrayList 的构造器可以将其转变成真正的 ArrayList
fail-fast和fail-safe
Java集合的一种错误检测机制。当多个线程对集合进行结构上的改变的操作时,有可能会产生 fail-fast 机制。记住是有可能,而不是一定。例如:假设存在两个线程(线程 1、线程2),线程 1 通过 Iterator 在遍历集合 A 中的元素,在某个时候线程 2 修改了集合 A 的结构(是结构上面的修改,而不是简单的修改集合元素的内容),那么这个时候程序就会抛出 ConcurrentModificationException 异常。
例子:
List<String> fruits = new ArrayList<String>() {{
add("apple");
add("orange");
add("orange");
add("chestnut");
}};
for (String fruit : fruits) {
if (fruit.equals("orange")) {
fruits.remove(fruit);
}
}
System.out.println(fruits.toString());
代码抛出CMException异常,在增强for循环中,集合遍历是通过iterator进行的,但是元素的add/remove却是直接使用的集合类自己的方法。这就导致iterator在遍历的时候,会发现有一个元素在自己不知不觉的情况下就被删除/添加了,就会抛出一个异常,用来提示用户,可能发生了并发修改。
java.util.concurrent包下的容器都是fail-safe的,可以在多线程下并发使用,并发修改。同时也可以在foreach中进行add/remove 。
例子:
List<String> fruits = new CopyOnWriteArrayList<String>() {{
add("apple");
add("orange");
add("orange");
add("chestnut");
}};
for (String fruit : fruits) {
if (fruit.equals("orange")) {
fruits.remove(fruit);
}
}
System.out.println(fruits.toString());
以上代码,使用CopyOnWriteArrayList代替了ArrayList,就不会发生异常。
fail-safe集合的所有对集合的修改都是先拷贝一份副本,然后在副本集合上进行的,并不是直接对原集合进行修改。并且这些修改方法,如add/remove都是通过加锁来控制并发的。 所以,CopyOnWriteArrayList中的迭代器在迭代的过程中不需要做fail-fast的并发检测。(因为fail-fast的主要目的就是识别并发,然后通过异常的方式通知用户)。
Copy-On-Write
Copy-On-Write简称COW,是一种用于程序设计中的优化策略。其基本思路是,从一开始大家都在共享同一个内容,当某个人想要修改这个内容的时候,才会真正把内容Copy出去形成一个新的内容然后再改,这是一种延时懒惰策略。
CopyOnWrite容器即写时复制的容器。通俗的理解是当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。
CopyOnWriteArrayList中add/remove等写方法是需要加锁的,目的是为了避免Copy出N个副本出来,导致并发写。读方法未加锁,这样做的好处是我们可以对CopyOnWrite容器进行并发的读,当然,这里读到的数据可能不是最新的。因为写时复制的思想是通过延时更新的策略来实现数据的最终一致性的,并非强一致性。
CopyOnWrite容器是一种读写分离的思想,读和写不同的容器。而Vector在读写的时候使用同一个容器,读写互斥,同时只能做一件事儿。
CopyOnWrite并发容器用于读多写少的并发场景:白名单、黑名单、商品类目的访问和更新场景。
和ArrayList比较,它具有以下特性:
支持高效率并发且是线程安全的 因为通常需要复制整个基础数组,所以可变操作(add()、set() 和 remove() 等等)的开销很大 迭代器支持hasNext(), next()等不可变操作,但不支持可变 remove()等操作 使用迭代器进行遍历的速度很快,并且不会与其他线程发生冲突。在构造迭代器时,迭代器依赖于不变的数组快照
迭代器
Iterator接口中提供了很多对集合元素迭代的方法。每个集合中都有可以返回迭代器对象的方法iterator()。迭代器在迭代的过程中可以删除底层集合的元素。
Iterator和ListIterator的区别?
- Iterator可以用来遍历Set和List集合,但是ListIterator只能遍历List
- Iterator对集合只能向前遍历(next());而ListIterator可以向前遍历(next()),也可以向后遍历(previous())
- ListIterator实现了Iterator接口
IO流
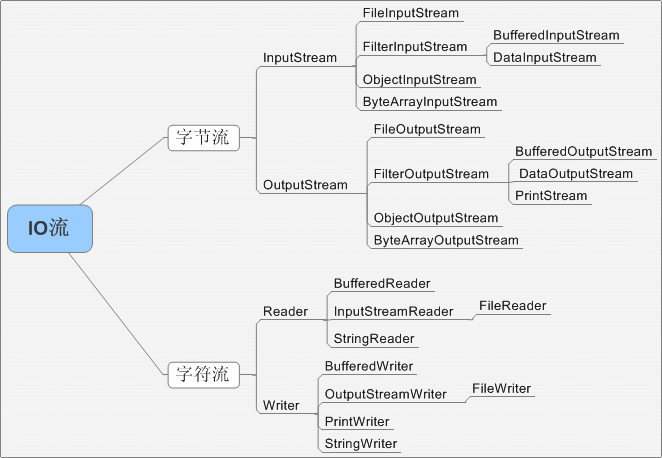
BIO、NIO和AIO
— 待续